Running LLM evals right next to your code
One of the first things you learn when going down the path of building applications with LLMs is that you need evals. Evals are basically like traditional software tests, but for interactions with the LLMs. Because LLMs are not deterministic, this is typically done by assigning scores between 0 and 1 to results, based on some scoring mechanism. Various platforms for storing and displaying eval results exist already, but wouldn’t it be nice if they could live in your existing test system, and be run and displayed in CI, just like your tests? I’ve explored just that, and in this post, I’ll show you what I found. It involves a SQLite database for tracking results over time, PR comments with Markdown tables, and a lot of Github Actions workflow YAML.
Note: I’ve been looking for an eval pipeline for a while. My applications are mainly written in Go, but there is actually nothing Go-specific in the approach you’re about to read about. If you have a way to run evals in your language and tooling of choice, you should be able to build something similar, or reuse some of what I’ve built.
Running evals as part of your application code §
In order to evaluate LLM prompts/completions, you’ll typically have some sort of automated eval system in place. Whether that’s a Jupyter notebook you can re-run manually on changes, or a more systematic approach where the evals are hooked into your application code using something like autoevals, it doesn’t really matter. What matters is that you can see and compare results from your evals, to see whether you’re improving the system with your changes, or not. Without evals, you’re just guessing and flying blind. Your AI product needs evals.
I’m building something like this for Go as I’m learning more about what kind of tooling I need for my LLM-powered applications, including evals. But I also needed a way to run and display eval results as part of every change, preferably as part of my CI pipeline. I mostly use Github for code hosting and CI/CD, so that was a natural starting place. It’s fairly easy to integrate the CI pipeline with an external platform like Braintrust, LangFuse, or LangSmith, but what if I wanted to show the results directly on Github, right in my PRs?
So evals are just like tests in CI, right? §
Not quite. The big difference to your test harness is that it’s necessary to look at eval results over time. Are you improving your results across changes, PR by PR? You want to be able to look at trends. Unless you have broken tests, your tests generally all pass on every change. So eval results are actually more like code test coverage, where you want to make sure that the code base is adequately covered by tests, and that the number improves or at least stays consistently high over time, across changes.
With code coverage, the picture is actually quite the same as with evals: external platforms exist to track these changes over time (such as Coveralls), and you often hook into those in CI for viewing code coverage.
But as already mentioned, I didn’t want that. External platforms change all the time, get new ownership, new policies, new pricing. But what lives with your code, and you can run on your own machines, is forever. Forever enough for our purposes, anyway.
Github CI obviously isn’t running things on my own machines, but their Github Actions workflows are basically just instructions on how to run tools already in or near the code base, so that’s close enough for me.
Viewing and tracking eval results over time §
So running evals as part of the code base (in my case, hooking into the test suite) is actually easy enough. I’m hooking into the Go test tooling, and for each eval, basically writing a JSON line to a file with the eval result.
I then built a little tool, fittingly named evals, to parse the eval results from this file. It currently does two things:
- Opens a SQLite database file called
evals.db, which has anevalstable with columns like experiment name (for grouping evals by experiment), eval name, metadata, and of course eval scores. (You can see the full schema in the evals repo.) For each eval result from the JSON lines file, it writes a row to this table. - For each eval result, it also writes a Markdown table row and prints it to STDOUT. If previous results for this eval name exist, we also display the change: whether it has improved, worsened, or stayed about the same.
Can you see where this is going?
If we can figure out a way to share the SQLite database file across CI runs, and show the Markdown table on our PRs, we’ve already come a long way.
Turns out, Github Artifacts and PR comments are the answer!
Artifacts can only live for a maximum of 90 days, but if we just make sure that our CI workflow runs at least every 90 days, we should be able to keep our state. Good enough for now.
The CI workflow §
Here’s the relevant parts of the workflow:
name: CI
on:
push:
branches:
- main
pull_request:
branches:
- main
workflow_dispatch:
schedule:
- cron: "7 0 * * 2"
concurrency:
group: ${{ github.workflow }}-${{ github.ref_name }}
cancel-in-progress: ${{ github.ref_name != 'main' }}
jobs:
evaluate:
name: Evaluate
runs-on: ubuntu-latest
if: ${{ github.triggering_actor != 'dependabot[bot]' }}
steps:
- name: Checkout
uses: actions/checkout@v4
- name: Setup Go
uses: actions/setup-go@v5
with:
go-version-file: go.mod
check-latest: true
- name: Get dependencies
run: go mod download
- name: Install evals
run: go install maragu.dev/evals
- name: Download evals.db
id: download-artifact
uses: dawidd6/action-download-artifact@v7
with:
name: evals.db
branch: main
if_no_artifact_found: warn
- name: Evaluate
run: |
go test -run TestEval ./...
evals | tee evals.txt >> $GITHUB_STEP_SUMMARY
env:
OPENAI_KEY: ${{ secrets.OPENAI_KEY }}
ANTHROPIC_KEY: ${{ secrets.ANTHROPIC_KEY }}
GOOGLE_KEY: ${{ secrets.GOOGLE_KEY }}
- name: Upload evals.db
uses: actions/upload-artifact@v4
id: evalsdb
with:
name: evals.db
path: evals.db
if-no-files-found: error
- name: Add evals comment to PR
uses: actions/github-script@v7
if: ${{ github.event_name == 'pull_request' }}
with:
script: |
const fs = require('fs')
const table = fs.readFileSync('evals.txt', 'utf8')
github.rest.issues.createComment({
owner: context.repo.owner,
repo: context.repo.repo,
issue_number: context.issue.number,
body: `# Evals\n\n${table}\n\n[Download evals.db](${{ steps.evalsdb.outputs.artifact-url }})`
})
Let’s quickly step through what it does.
- It runs on every push to the main branch, as well as on PRs toward that branch. Nothing new here. But it also runs on a schedule every week, so we make sure there’s always an artifact associated with the main branch (see below).
- It sets up the environment and installs the
evalstool described above. - It then uses the dawidd6/action-download-artifact@v7 action to download the newest
evals.dbfrom the main branch. This wasn’t obvious to do with the official download-artifact without having to use the Github API to figure out some metadata, so I opted for a third party solution here. - It runs the
evalstool and writes the Markdown table output both to$GITHUB_STEP_SUMMARY(which is a variable that holds a file path) as well as to anevals.txt. The content of$GITHUB_STEP_SUMMARYwill be published to the PR Actions summary. - It uploads the newly updated
evals.dbas an artifact. For PRs, this is just so you can download the database file to your laptop and inspect it manually if you need to. When merging to the main branch, this artifact is the main eval results database file! - Last but not least, we post a comment to the PR with the results table and a link to the artifact, for easy viewing and access.
The PR comment then looks something like this:
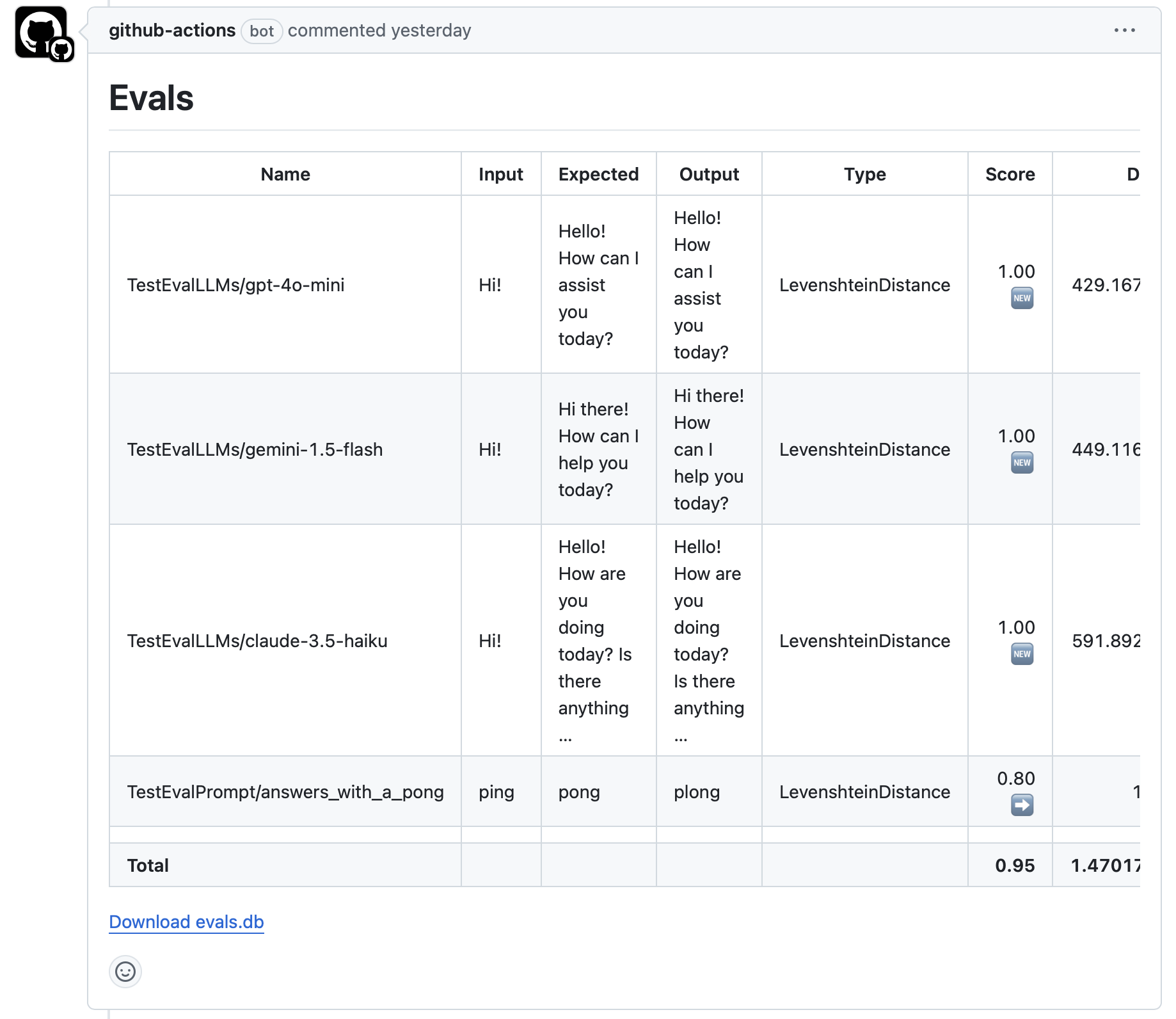
Pretty cool! The table can obviously be improved to make a better overview, and a graph with a trendline wouldn’t hurt, but this is much better than running everything manually all the time. Or not running evals at all.
Wrapping up §
So what we have now is:
- Visibility into eval results and their changes on every PR.
- A SQLite database file with all eval results over time.
What we don’t have is this:
- Nice graphs to see changes visually.
- A way to see current eval results for the main branch, in a table or otherwise, because there’s no associated PR.
I’ll keep evolving this approach unless I find a better way to do this. Feel free to tag along by subscribing to updates to this blog and/or the repos I’ve linked above. And hit me up on ze socials if you’ve got ideas for improvements, comments, or just want to tell me it’s cool. 😎

I’m Markus, an independent software consultant. 🤓✨
See my services or reach out at markus@maragu.dk.
Subscribe to this blog by RSS or newsletter: